Exploratory Data Analysis
The only data set we are using to solve the playlist prediction problem is the Spotify Million Playlists data set. This data set contains individual statistics for each of the one million spotify playlists, such as playlist name, number of followers, last modified, a list of each individual song in that playlist, and several other columns.
The first potential approach we explored was based on the assumption of latent classes, then using maximum likelihood methods to parameterize the latent classes and classify new songs. We theorized these latent classes might end up capturing some genre information, given the large amount of playlists with similar, genre defining names like “metal” or “disney”. Each spotify playlist in the data set would be categorized into an arbitrary latent class. Then, given an inputted playlist, we could predict new songs based on the playlist’s likely latent class. To explore the possibility of playlists with similar names containing similar songs, we first looked at the top 20 most common playlist names. Below is a graph of the similarity index for the 20 names, which we define as the average percentage of songs present in both of 2 randomly selected playlists of the same name. We ran this exercise on 10 percent of the data - 100,000 playlists. Names with a high similarity index would theoretically be more prone to suggesting the most popular songs of those playlists, while names with a lower similarity index might be more prone to suggesting a wider variety of songs rather than the few most popular songs of playlists with those names.
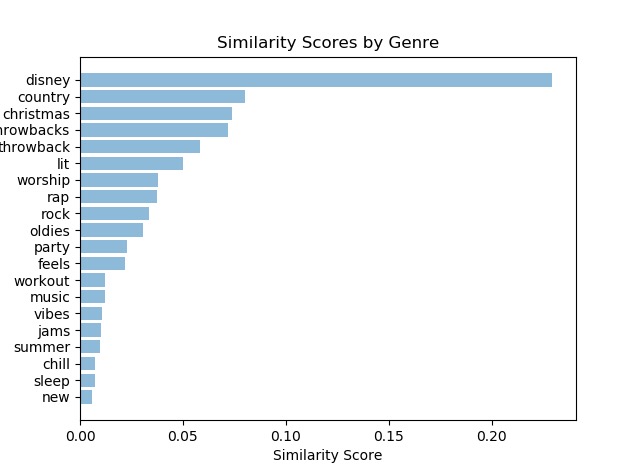
Based on these findings, we believe that there are a decent number of playlists that are similar. That is to say: many of the millions of songs are rarely touched. An alternative approach that evaluates on a metric such as novelness of suggestion might hold that effective playlists would introduce listeners to some of those songs that are currently untouched. However, considering our current metric of evaluation is based on successfully completing playlists based off a slice of the initial part of the playlist, this is less of a concern. This is all a somewhat roundabout way of saying that the fact that there are many playlists with fairly high similarity indexes plus the fact that playlists are using many of the same songs over and over again signals that collaborative filtering can be an effective route to tackling this problem, as collaborative filtering is good at predicting similar songs but is less effective at generating novel suggestions.
The main benefit of collaborative filtering in relation to this problem, however, lies with the nature of the data we are working with. Collaborative filtering completely ignores all features relating to specifics of the actual songs themselves. Content-based models might use features such as lyrics of a song, or waveforms of their audio data. Collaborative filtering, on the other hand, only utilizes information about which playlists each song is included in. This makes it perfect for use on the Million Playlists Dataset, given that this dataset has no song-specific feature information. The dataset is in essence simply a list of songs in playlists, which is exactly the type of data collaborative filtering uses as inputs. Collaborative filtering does not leverage or make inferences about any meta-information about playlists such as intended genre or mood in the way that a hybrid of content-based approach might. However, our EDA showed that in many cases, the problem is a fairly straightforward one where people have fairly straightforward aims and create fairly similar playlists. This signals that other approaches may overfit the data and miss the elegance of a simple model.
We also investigated how we might weight playlists. We believed that playlists with more followers might deserve more influence on the final model than models without many followers. We investigated the distribution of followers for playlists and found the following breakdown.
| Percentile | Number of followers |
|---|---|
| 0.50 | 1 |
| 0.75 | 1 |
| 0.90 | |
| 0.95 | 3 |
| 0.99 | 8 |
| 0.9999 (top 100 playlists) | 1995 |
75 percent of playlists have only one follower. In fact, the 99th percentile only has 8 followers. Within the most popular 1% of playlists, there is small subset of playlists that have 1000 followers.
One might be tempted to consider these popular playlists as outliers, perhaps to be discarded. However, we theorized that popular models might have important insights into listener preference and therefore should actually be given more weight in potential models. Songs that appear disproportionately in popular playlists but not in the rest of the population could serve as good recommendation choices. Thus, we calculated the most popular choices in the subset of popular playlists and the most popular choices in the data set as a whole:
| Whole dataset | 100 most popular playlists | ||
|---|---|---|---|
| Song name | Percent of playlists | Song name | Percent of playlists |
| Humble | 4.35% | Sign of the Times | 11% |
| One Dance | 4.34% | Chasing Cars | 7% |
| Broccoli | 4.13% | Iris | 6% |
| Closer | 4.11% | Let it Go | 5% |
| Congratulations | 4.00% | Feel it Still | 5% |
| Caroline | 3.52% | Scar Tissue | 5% |
| iSpy | 3.51% | Drops of Jupiter | 5% |
| Bad and Boujee | 3.50% | Fix You | 5% |
| Location | 3.50% | The Scientist | 5% |
| XO TOUR Llif3 | 3.49% | She Will be Loved | 5% |
The sample size of the popular playlist is somewhat limited - it’s only 100 playlists. The songs in the top 10 of the popular playlists covers a wider range of songs. While not explicitly included in the data, all the songs in the overall playlist count were released in the last three years. All but one (Closer) could be classified as Hip-Hop and R&B. Most songs in the most popular playlists were not exclusively from Hip-Hop and R&B and spanned a more expansive range of release dates: “Feel it Still” was released in 2017 but “Iris” was released in 1998.
The similarity score reinforces this finding that the most popular playlists used a broad range of songs. The similarity score between the top 100 playlists was quite small, at 0.002. This means the most popular playlists might be useful for broad recommendation for many different types of playlists, due to the large range of songs they include.